Using Redis to speed up incrementing counter value
What is the problem?
Imagine there is system in which there is a counter value that needs to be updated fairly frequently. This counter is required to be consistently throughout the whole system so it needs to be persisted to the database. For example, say this system is a voting system, and counter is number of votes. Whenever there is a new vote, the vote counter need to be incremented. To support these requirements, there are two tables: Item and Vote
|----------| |---------|
| item | | vote |
|----------| |---------|
|id | |id |
|name | |item_id |
|vote_count| |---------|
|----------|
Technically, item.vote_count is not entirely necessary to keep track of the number of votes per item. As vote_count can also be obtained by counting the number of rows in vote table having the same item_id. The reason of having a vote_count is because this value is looked up frequently enough that counting it very time from vote table is fairly slow, especially when new vote are cast frequently too.
For every new vote, we would send a transaction to the database to insert the vote and update the vote_count value:
start transaction;
insert into vote(item_id) values(13);
update item set vote_count = vote_count + 1 where id = 13;
commit;
This solution is generally pretty good. And in many cases, there will not be any problems at all. However, if the system needs to support a big amount of vote requests in a short a time (say 1000 votes every seconds), there will probably be a performance problem. As vote_count needs to be updated for every new votes, and update queries are slower than insert queries so when inserting vote is fast the system as a whole is still slow because vote_count needs to be updated as well.
One solution to this problem is that vote_count can be offloaded to another service that is better at handling incrementing counter, and synchronize it back to the database in due time. A good candidate for this solution is Redis, as an in-memory key-value database, Redis is extremely fast to handle counter value.
Using Redis
With the addition of Redis, the system looks like this:

So now whenever there is a new vote. The application server needs to do two things: first, it needs to insert the new vote into the database with insert into vote(item_id) values(13);, seconds it needs to increment the counter in Redis with incr id_13. This is surely much faster than inserting vote and updating counter in the database. So far so good? Well, not exactly?
The problem is Redis might not have the current counter value. For example, we might just spin up a new Redis instance and it does not have any keys at all, so if it receives a request to increment a non-existed key, it will simple assume the current value for that key is 0. This will be only acceptable for the first vote ever of an item, if an item is already voted multiple times, we would have a big trouble here.
In order to solve this, the server has to check for the key existence in Redis before incrementing it. If the key is not there, Redis will notify the server without incrementing anything. The server in turn will grab the value from the database, increment, and persist it the Redis.
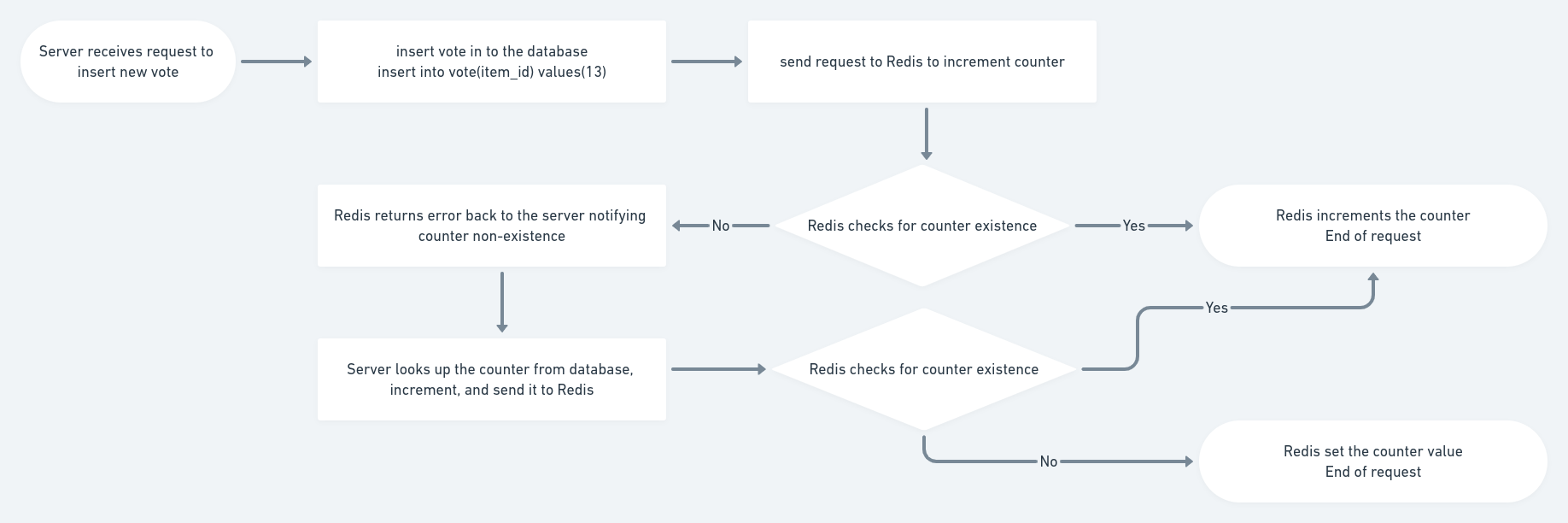
One important thing needs to note in this new flow is that Redis checks for the counter existence the second time when it receives the new value from the server, and it only sets the value if key still does not exist. The second check is necessary to ensure the correctness of the value when there are multiple instances of the server. When many servers receive requests to insert votes at the same time and the counter does not exist in Redis, they will all go look up, increment the value from the database, then send to Redis. The problem is that all of them will get the same value from the database and increment it only once, so the new value they have is only greater than the current one by 1 which is wrong because they are multiple new votes:
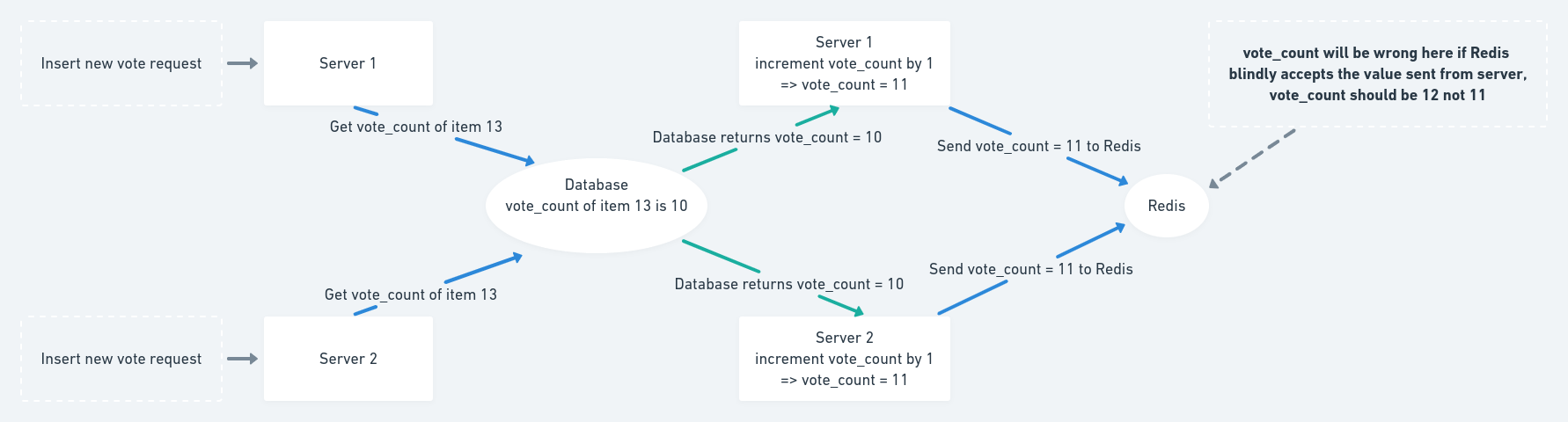
To solve this problem, Redis will simple check for the counter existence one more time and only set the value if it is not there. Otherwise, Redis will fall back to the normal behaviour which is to increment the counter.
Synchronization control
At this point, our system is able to insert votes and increment the vote counter efficiently. However, if we go to the database and look up a counter value, we will not have the correct value there because it is stored in Redis. Therefore, the system needs to synchronizes counter values back to the database. Redis only acts as a temporary database to keep the values, we do not want to leave them there permanently as it might make more difficult and complicated to look up counter values later on. This depends on the situation of course, there are times when it is actually a good idea to use Redis as a permanent data store too. But in this case, the requirement is to have the value in the database.
In order to do this, the system would need to set up some workers that will look up the values from Redis and save back the database. These workers can be the same application servers we already heave, or different servives required to set up seperately. That totally depends on the circumstances. However, regardless of their nature, they would need to do these things:
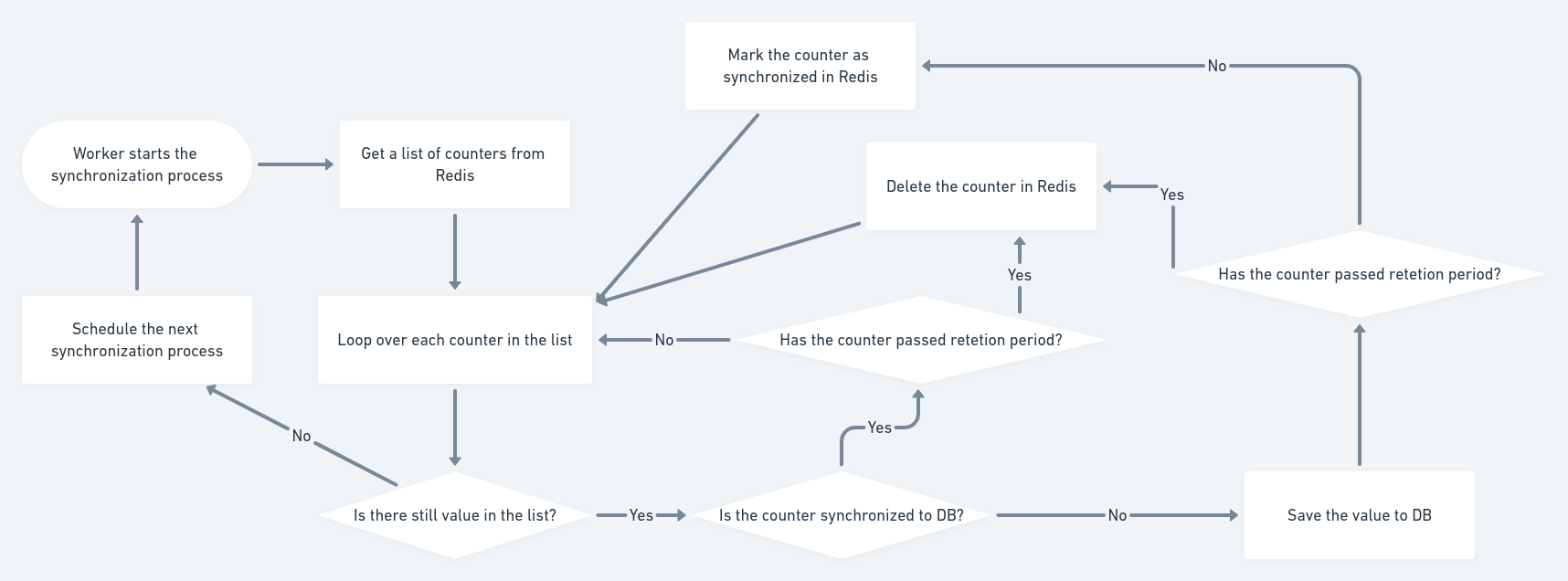
This synchronization flow actually does more than simply saving counters to the database. It also deletes counters from Redis after saving. However, it is not a good idea to delete counters immediately after saving, as that forces application servers to look up counters from database more often when upvoting. That is the thing we want to improve in the first place. On the other hand, we do not want to leave counters in Redis permanently as that would occupy a lot of memory space and slow down synchronization when the number of counters is large enough.
To satisfy all these requirements and problems, we introduce a new information for counter which is retention period. This new value indicates how long a counter should stay in Redis after synchronization. The key name for this value can be item_13_expired, and the value is a timestamp indicating when the item_13 is expired. This key can be controlled by application servers when they set or increment counters. For example, they can set expire time to be 10 minutes in the future whenever set or increment a counter.
One more key which is used by the synchronization flow is item_13_saved. This value indicates if a counter has been saved to database. We need this as we want to limit saving to database as much as possible because that would slow down the database which is bad. And re-saving an already-saved value is totally unnecessary.
This flow also allows multiple workers to synchronize counters at the same time without any concurrency problems. Of course, that also depends on the scripts that are used by Redis to work with these keys. One need to be careful not to delete an unsave counters for example. Below are some sample Lua scripts that can be used by Redis to work with counter and its metadata keys:
----------------------- to get list of counters and their related metadata values -------------------------------
local cursor = redis.call("get", "item_synchronization_cursor") or 0
local scanResults = redis.call("scan", cursor, "match", "item_*", "count", 1000)
redis.call("set", "item_synchronization_cursor", scanResults[1])
local keys = scanResults[2]
local result = {}
for i=1,#keys do
local key = keys[i]
local id = string.match(key, "item_(%d+)$")
if id then
table.insert(result, id)
table.insert(result, redis.call("get", key))
table.insert(result, redis.call("get", key .. "saved"))
table.insert(result, redis.call("get", key .. "expired"))
end
end
return result
----------------------- to get list of counters and their related metadata values -------------------------------
---------------------------------------- to mark counter as synchronized ----------------------------------------
local id = KEYS[1]
local savedValue = tonumber(KEYS[2])
local key = "item_" .. id
local curValue = tonumber(redis.call("get", key))
-- only marks as synchronized if input count and current count is the same
-- this condition prevents a concurrency bug when the counter has been updated since the last time it was retrieved
if savedValue == curValue then
redis.call("set", key .. "_saved", 1)
end
---------------------------------------- to mark counter as synchronized ----------------------------------------
----------------------------------- to delete a counter and its related keys ------------------------------------
local id = KEYS[1]
local savedValue = tonumber(KEYS[2])
local key = "item_" .. id
local curValue = tonumber(redis.call("get", key))
-- only marks as synchronized if input count and current count is the same
-- this condition prevents a concurrency bug when the counter has been updated since the last time it was retrieved
if savedValue == curValue then
redis.call("del", key);
redis.call("del", key .. ":_expired");
redis.call("del", key .. ":_saved");
end
----------------------------------- to delete a counter and its related keys ------------------------------------